Persistence
Persistence refers to that part of the domain model, which we could call the data model.
Data model
The data model consists of domain classes whose instances are saved in the storage. The following steps need to be accomplished to make domain class instances persistent.
- Definition and creation of the database tables, if using a database storage.
- Implementation of the
PersistenceMapperclasses, which map the domain classes to these tables, or anything else that is used as storage. - Implementation of the domain classes as subclasses of
Node. - Configuration of the persistence layer.
- Note
- If you are using the generator to create the application from a model (see Model), all necessary code will be generated automatically.
Database tables
Still the most common storage for web applications is a SQL database (e.g. MySQL). It is also wCMF's default storage. Although not strictly necessary it is recommended to use one database table for each persistent class, where each class property maps to one table column and each row stores one instance. The object identity is stored in the primary key column, which is named id by default.
- Note
- wCMF uses a table called
DBSequencefor retrieving the next id value used for insertion, since autoincrement columns are not supported on all database servers.
Primary keys
Primary keys are used to clearly identify an object in the database. They can consist of one (simple) or more (compound) columns. The default name for a primary key column is id. wCMF stores the primary key of an object together with it's type name in an ObjectId instance.
Relations
The following two relations types must be considered, when modeling the data tables:
- One-To-Many relations are realized by adding a foreign key column to the child table (many-side), which points to the parent table (one-side). This column is named fk _ + parent table name + _ id by default (e.g. fk_author_id).
- Many-To-Many relations between two domain classes, are established by defining a connection table. This table contains two primary keys, which point to the two connected tables.
Persistence Mappers
wCMF uses persistence mapper classes to communicate between the application and the persistent storage (see Architecture). These classes implement the PersistenceMapper interface, which defines methods for all persistence actions. By using this pattern wCMF does not make any assumptions about the actual storage, which can be flat files, a database, a remote service or anything else a mapper is able to handle. This approach also makes it easy to connect an existing storage to a newly created wCMF application.
To simplify the implementation of mapper classes, wCMF already contains a class hierarchy for a common mapping approach, which maps each concrete class to one database table (Concrete Table Inheritance). In this hierarchy AbstractRDBMapper handles the communication with the relational database, while NodeUnifiedRDBMapper defines the actual mapping rules. Application developers simply need to implement one subclass of NodeUnifiedRDBMapper for each persistent domain class, which declares the mapping of the attributes and relations of that class.
- Note
- All mapper classes, that are created by the generator are
NodeUnifiedRDBMappersubclasses.
Domain Classes
Domain class instances hold the data that are used in the application and persisted in the storage.
Persistent domain classes either inherit from
PersistentObject, which is a container with value getter and setter methods, or fromNode, which adds methods for managing relations.
These two classes are completely generic, the actual identity of the domain class - that is the properties and the relations - are defined by the related PersistenceMapper.
So if no additional domain logic is required in the domain class, it would be sufficient to use Node as domain class. But in many cases you will want to execute custom code for Persistence Hooks, Validation and other business logic and therefor create a custom subclass of Node.
- Note
- All domain classes, that are created by the generator are
Nodesubclasses.
Persistence Hooks
Persistence hooks are methods that are called at certain points of the lifecycle of an instance. The default implementation of these methods is empty - in fact their sole purpose is to be overwritten in subclasses on order to implement special functionality that should be executed at those points. PersistentObject defines the following persistence hooks:
Values, Properties and Tags
The following terms are important to know when working with wCMF's domain classes:
- Values are the persistent attributes of a domain class. You can think of them as class members. Values are accessed using the methods
getValueandsetValue. - Properties apply to domain classes and domain class values. They describe static features like the
displayValuesof the class or theinputTypeof a value. Properties are defined in the model as tags (see Chronos profile) and are accessed using the methodsgetProperty/setPropertyandgetValueProperty/setValueProperty - Tags are a special property used on values to group them by certain aspects. For example the edit forms in the default application only display domain class values that are tagged with
DATATYPE_ATTRIBUTEand only those attributes are editable in the translation form that are tagged withTRANSLATABLE. TheSEARCHABLEtag defines that an entity type should be included in the search index. Tags are defined in the model using the tagapp_data_type(see ChiValue).
Configuration
Entry point of configuring the persistence layer is PersistenceFacade (see Usage). The configuration mainly tells the facade which mapper classes are responsible for which domain classes. This assignment is defined in the TypeMapping configuration section. The following example shows the appropriate entries for the Author domain class:
Usage
PersistenceFacade is the main entry point to the persistence layer. It is used to create and retrieve PersistentObject instances. The following sections show some basic examples for using the persistence layer.
Loading objects
To load a single object, the PersistenceFacade::load method is used:
In the example the Author instance with id 1 is loaded.
A list of objects is loaded using the PersistenceFacade::loadObjects method:
This PersistenceFacade::loadObjects method provides several parameters that allow to specify which instances should be loaded and how the list should be ordered. The next sections explain these parameters.
Eager relation loading
When loading objects we generally distinguish between eager and lazy loading (see Lazy loading). By default PersistenceFacade performs lazy loading by using virtual proxies (instances of PersistentObjectProxy). That means that related objects are retrieved from the store, only when they are actually accessed. To perform eager loading, a BuildDepth value is passed in the method calls:
In this example the Author instance with id 1 is loaded together with all related objects recursively.
Instead of a BuildDepth value, an integer number could be passed indicating the depth of relations to load. The following image illustrates the build depth parameter for a simple model.
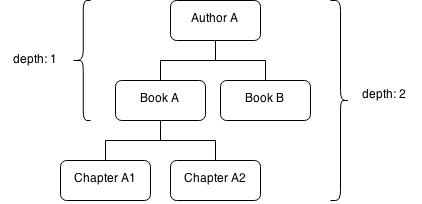
If using a build depth value of 1 the Author instance Author A will be loaded together with it's related Articles instances (Article A, Article B). A value of 2 will also load the Chapter instances (Chapter A1, Chapter A2). The default value is BuildDepth::SINGLE, which means that only the Author A instance is loaded. In the above illustration the value of 2 is equal to passing BuildDepth::INFINITE.
Sorting
When loading a list of objects, the default order of the PersistenceMapper class is used for sorting. This default order is defined in the model (orderby tag of ChiNode, see ChiNode / ChiManyToMany). Besides this, all loading methods (e.g. PersistenceFacade::loadObjects) accept an orderby parameter for explicitly setting a different order.
A list of already loaded Node instances is sorted by using NodeComparator in the following way:
Pagination
A common pattern for reducing the response time of an application when displaying large lists of objects is pagination. This technique splits the list into smaller parts (pages) that are displayed one by one. In wCMF the class PagingInfo implements the concept.
The following code shows how to load 25 Author instances starting from position 50:
Pagination is also possible over multiple entity types:
Searching objects
To search objects in the store the PersistenceFacade::loadObjects method is used. It allows to set the conditions that loaded objects should match.
In this example all Article instances with titles starting with A and release date 2014 or later are loaded.
Null values
Null values are matched/not matched using the following criteria:
Object queries
More complex use cases are supported by the ObjectQuery class. For example it allows to set search constraints on connected objects as shown in the following example:
In this example all Author instances are loaded which have names starting with A or B and which have Article instances connected that are created in the year 2014.
It is possible to combine several object queries to apply pagination over multiple entity types using the UnionQuery class:
Besides this, wCMF integrates the Lucene search engine in the class LuceneSearch.
Iterating objects
wCMF provides several iterator classes for traversing objects and values.
NodeIterator allows to traverse object graphs starting from a root Node. The algorithm used is depth-first search.
NodeValueIterator is used to iterate over all persistent values of a Node.
PersistentIterator allows to traverse object graphs as well, but it's state could be persisted to split the iteration of large lists into smaller parts.
Creating / Modifying objects
Domain class instances are created by calling the PersistenceFacade::create method or simply the class constructor, where the first approach is preferred over the second because it also sets the default values on attributes.
Changes on instances are persisted automatically, when the current transaction is committed (see Transactions). Objects are removed from the store by calling the PersistentObject::delete method.
Validation
Before persisting objects, their content has to be validated according to the application requirements. Validation is handled in PersistentObject::validateValue (for a single attribute) or PersistentObject::validateValues (for the complete instance). These methods are called when values are changed via PersistentObject::setValue or right before persisting the object in AbstractMapper::save. Both validation methods throw a ValidationException, if validation fails.
Validation types
The actual validation is delegated to the Validator::validate method, which gets a validation description string passed. This string defines a single ValidateType or a combination of those. The ValidateType::validate method accepts an associative array of configuration options, that is encoded into a JSON string when being used in the validation description string. An additional validation context might be passed to the method (e.g. the entity instance and the currently validated entity attribute), when validation entity values.
To define which validation should be applied to a domain class attribute, the tag restrictions_match is used in the model (see ChiValue).
Currently the following validation types exist (the examples show their usage in a validation description string):
Date validates against a date format, e.g.
Filter validates against a PHP filter (see filter_var), e.g.
Image checks width and height of the referred image file e.g.
RegExp validates against a regular expression (see preg_match) e.g.
Required checks if the value is not empty e.g.
Unique checks if the value is unique regarding the given entity attribute e.g.
- Note
- The validation type is derived from the part of the configuration string, that precedes the first colon.
Custom validation types can be added in the configuration. For example after adding myValidator (implemented in MyValidator class):
it is used in the following way:
Complex validation
The described validation types only operate on one attribute. If more complex validation is required, e.g. if dependencies between several attributes exist, the method PersistentObject::validateValue could be overriden in the appropriate domain class.
Concurrency
When two or more users try to access the same object at the same time problems like lost updates might occur. These issues are avoided by concurrency control mechanisms, typically object locking.
Locking
wCMF provides two locking strategies:
- Pessimistic locking: An explicit lock is obtained by one user, that blocks write access to the object for other users until the lock is released.
- Optimistic locking: A copy of the initial object data is stored for each user and checked against later, when the user tries to store the object. The operation fails, if another user has updated the object data in the meantime.
For more detailed information see database locks.
Lock instances are obtained by calling ConcurrencyManager::aquireLock and released using ConcurrencyManager::releaseLock like shown in the following example:
The actual storage and retrieval of Lock instances is delegated to LockHandler. The following lines show the concurrency configuration in the default application:
As you can see the LockHandler implementation is exchangeable.
Transactions
wCMF supports database transactions. There is only one transaction at the same time and it is be obtained using the PersistenceFacade::getTransaction method. The transaction has an active state, which is set in the Transaction::begin method and reset on commit or rollback.
The following example shows, how to use transactions:
- Note
- Even if not obtained explicitely, there is always a transaction existing in the background, to which objects loaded from the store are attached. But to persist changes when doing a commit, the transaction has to be set active before loading or creating the object.
There are situations where you want to let the current transaction ignore changes made to newly created objects or objects loaded from the store. In these cases you can use the method Transaction::detach to disconnect the object from the transaction.
Dry runs
wCMF applies all database changes directly when committing the database transaction.
But there are situations where this is not desirable or just not possible. For example you might want to review the changes bevor applying them finally. Or the work to be done inside the transaction would exceed the provided resources (time and/or memory) and therefor must be split into smaller pieces but still need to be carried out in a one fails, all fail manner. A typical use case for the latter would be a large data import from external sources.
For these cases wCMF transactions offer the Transaction::commitCollect method, which returns all statements that would be executed, if the transaction would be commited regularly.
The following script shows how to do a dry run first and commit the collected statements later: